
发现要爬虫的目标网址的数据在PDF上,一开始用”smalot/pdfparser”这个包去解析PDF文件,但是发现有的PDF可以解析,有的报TCPDF_PARSER ERROR: Invalid object reference: Array这个错,去issue上查了下别人说是PDF版本不是1.4造成的,但是我看了解析不了的pdf版本就是1.4的,相同版本有的可以解析有的不能解析,唯一的不同就是编码软件不一样,查了很多资料解决不了,逐放弃这个用这个包解析PDF
php有很多PDF包,但是就pdfparser这个包简单好用,别的要么解析不了要么很麻烦,所以放弃用php解析了,转而寻找其他语言比如Python,java处理,但是想了一下又懒得部署一套其他语言的环境,最后想到用linux来解决这个问题
linux安装pdftotext,用这个把pdf转成TXT,在用php读取TXT达到曲线救国的目的,linux安装pdftotext很简单,命令为yum install xpdf,随后pdftotext -v查看是否安装完成,PDF转txt的命令为pdftotext test.pdf test.txt,如果pdf里有中文的话要指定编码pdftotext test.pdf test.txt -enc UTF-8,在php里实现为
1 | exec("pdftotext test.pdf text.txt", $output, $ret); |
然后对text.txt的数据进行处理就行,处理的过程中发现一个奇怪的东西,如图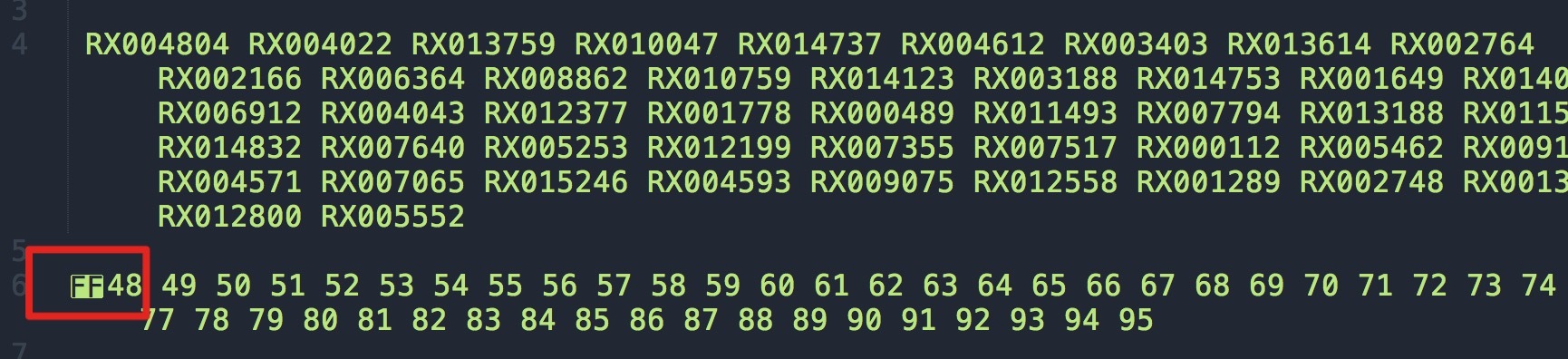
两个大写的FF,一脸懵逼,突然想起来以前遇到过一个差不多的EOT(传输结束符),原来是ASCII码中的换页符号,用preg_replace(“/\f/i”, ‘’, $str)去除即可,有空要好好的研究下ASCII码,免得看到一脸懵逼
—————2018-06-12更新————————-
目标网址进行了一次升级,模糊处理的pdf并打上了水印,pdftotext已经识别不出了
原pdf
现pdf
所以采取了新的方法,先将pdf转成png图片,在用百度OCR识别图片内容。
将pdf转成图片用的是imagemagick,安装方法自行百度,命令为
1 | convert -verbose -colorspace RGB -resize 1800 -interlace none -density 300 -quality 100 path/test.pdf path/test.png |
然后我又对图片进行了裁剪,命令为
1 | convert path/test.png -gravity northwest -crop 35%x250%+300+100 path/test.png |
裁剪后的效果
然后处理了一下水印,我这边处理的方法是用convert替换水印的颜色为背景色
1 | convert path/test.png -alpha set -channel RGBA -fuzz 10% -fill "rgb(239,239,239)" -opaque "rgb(255,255,255)" path/test.png |
然后提高了图片的分辨率
1 | convert -resize 1000x5000! -interlace none -density 300 -quality 100 path/test.png path/test.png |
最后调用百度OCR识别图片内容,只要图片处理的好,大部分内容可以成功识别出来